
Avail is a modular data availability blockchain. For most people, that’s not much of an explanation. Below are a few clear metaphors for understanding modular blockchains, one of the most important concepts in the Web3 space.
The metaphors mostly describe one potential use case for Avail - the Validium solution for Layer 2s. Future posts will explore other use cases like Avail-native applications. So, read on to level up your Web3 game, and along the way, understand what Avail is and why it’s important.
If we want the entire world to join Web3, blockchains will need to handle more transactions. But the more functions we ask a blockchain to perform, the less likely it is to be able to scale. Avail takes some of those functions off their plate. This is our take on why the modular blockchain approach is better suited for scaling than monolithic blockchains.
Let’s start by getting specific about how Avail empowers a blockchain to scale.
Avail’s core benefit is that it allows other chains to make their transaction data available off their own chains. Typically, blockchains have three main functions.
- Data Availability: Record transaction data, and provide the order in which transactions occurred.
- Execution: Run/process every transaction from the chain’s inception to the transactions happening at this moment to make sure the state is always correct.
- Settlement: Finalizes transactions, and provides security for all of the chains settling to it.
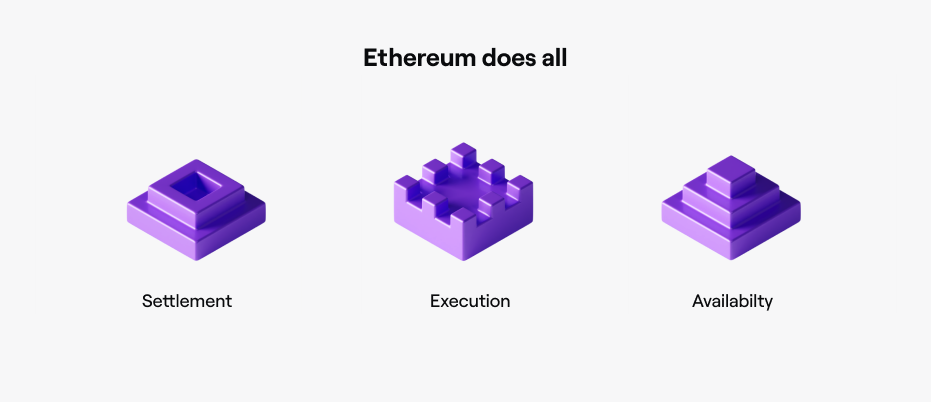
Right now, blockchains like Ethereum are capable of - and are often asked to do - all of these things at once.
Special blockchains like Layer 2 rollups can handle specifically the execution part. But rollups still need to store their data somewhere. Currently, they "roll up" the transactions they execute into a compressed format and post them to Ethereum. To accompany this transaction data, ZK rollups also send a proof of execution, and the final state they arrived at. This system, is reliant on Ethereum as both the settlement layer, and the layer that stores the transaction data.
Avail focuses on just making sure data is available, so that more specialized chains can focus on creating their own novel execution environments.
Let’s look more deeply into how this works in the Avail modular system.
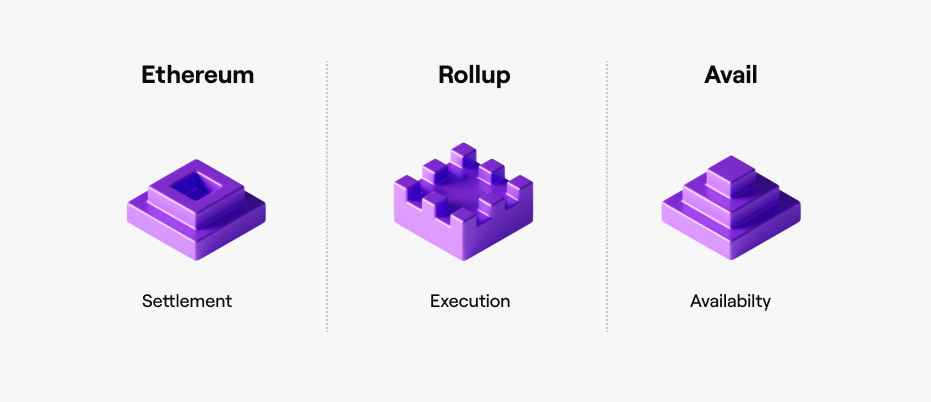
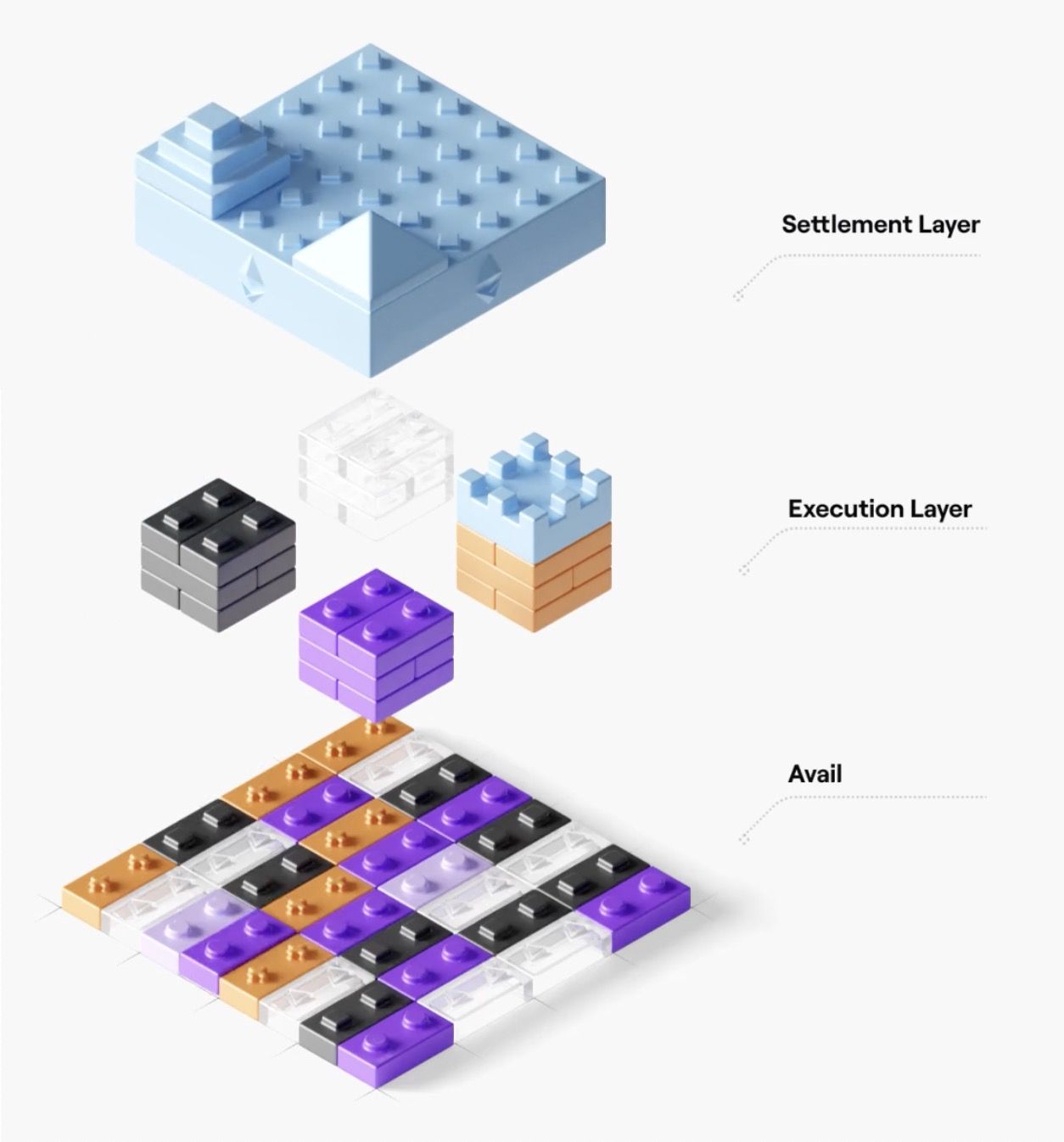
The Modular System
We think of each of these three pieces a bit like building blocks. At the top is Ethereum, the settlement layer. Ethereum has the final say on transactions, and handles disputes if they arise between other chains. In the middle are execution environments focused on handling as many transactions as possible. This is where Layer 2 rollups sit. Lastly, at the bottom is the data availability layer.
Settlement Layer
In a modular setup, the relationship between settlement layers and execution layers is similar to the relationship between your bank, and credit card provider, respectively. While you can certainly provide your banking info for each purchase you make, many people make purchases on their credit card, which in turn makes a single charge to your bank once a month.
Transactions are queued up on your credit card before they are settled against your bank account. Transactions may be pending for some time before your bank account balance changes. But your bank functions as the source of truth for your balance.
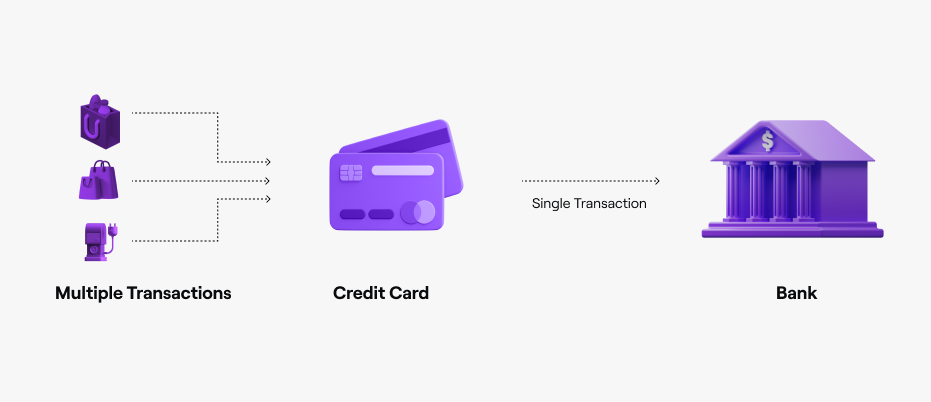
We believe that the core functionality Ethereum should provide is to act as this source of truth; to settle all the transactions and activity that happens on other chains.
This is because we want the settlement layer to be the most secure, and decentralized component of the stack.
Unfortunately, settlement layers like Ethereum only have so much space per block. In a modular system, other layers relieve the settlement layer of having to perform any tasks beyond providing security so that more block space can be freed up.
Execution Layer
Because Ethereum is focused on security, execution environments are designed to focus on scalability.
Rollups for example take execution off-chain. They’re tasked with executing transactions locally and periodically posting all the transaction data they’ve received and executed back to Ethereum.

Imagine two friends go on a trip. Jake pays $40 for gas, while Mark pays $20 for food. Rather than have Jake pay Mark $10 (to split food), and then have Mark pay Jake $20 (to split gas), Jake could just tell Mark he owes him $10.
Right now, rollups are required to both do all the calculations to figure out who owes who, and tell Ethereum (the settlement layer) about each independent transaction.
In the above example, they would be telling Ethereum how much each person paid for gas, and for food, as opposed to just how much one person owes the other. This is so that if the rollups go offline, or try to lie (i.e., one of your “friends” says you owe them $20 for something you paid for), you can still check by tracing all transactions back to their origin.
While there are significant cost savings as a result of taking the execution part off-chain, they need to continuously post transaction data back to a settlement layer, to Ethereum. And even though they’re compressing thousands of transactions off-chain to a single transaction on Ethereum, that one transaction can be quite expensive.
In the graphic below, the settlement layer is represented by a base that other building blocks can attach themselves to. It can receive the smaller colored building block pieces (individual transactions), and the “tops” that are generated by an execution layer after grouping together - in this example - 6 building blocks of the same color (execution proofs).
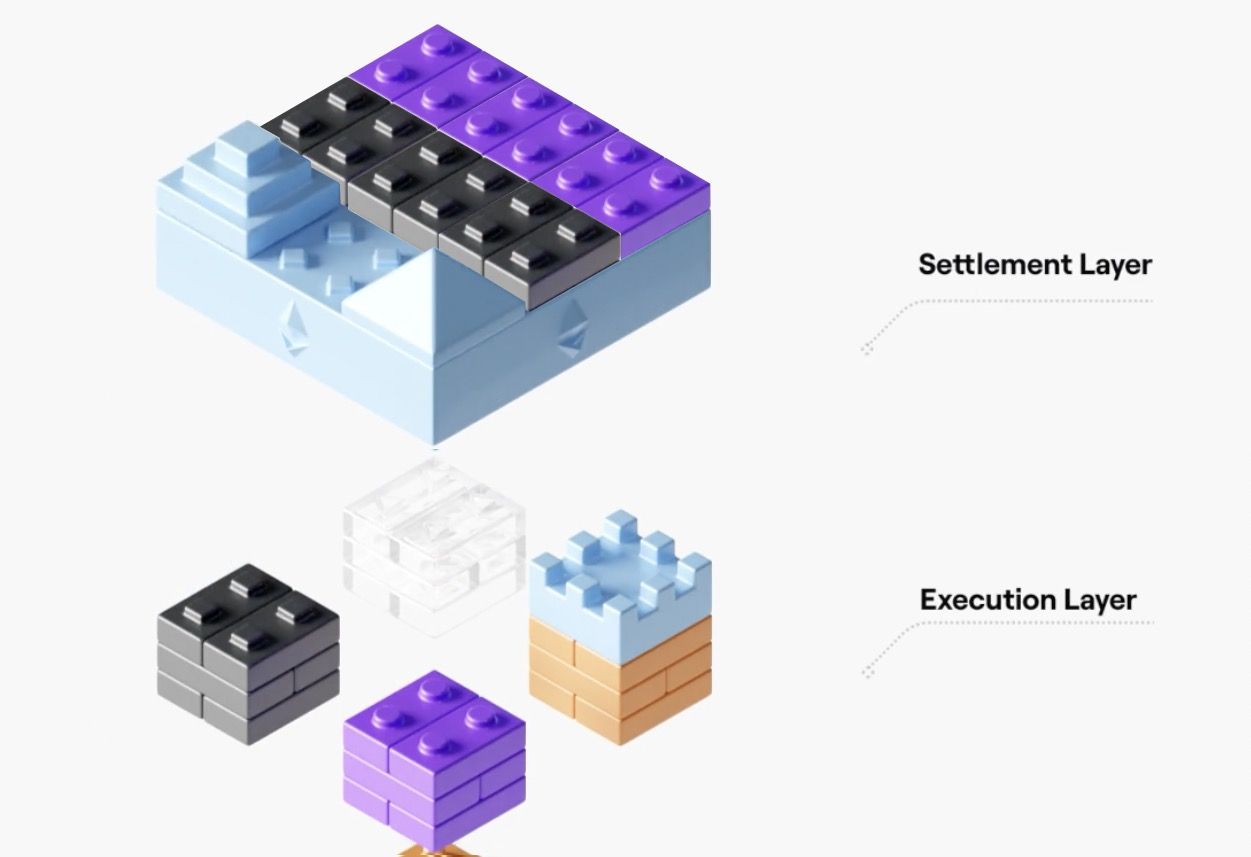
This model above specifically represents two zk based execution environments rolling up transactions, and creating proofs of execution that they then post to a settlement layer alongside the history of transactions they executed.
While taking execution off-chain alone is valuable, the rollups of today are asked to post both the tops (proofs) they create, and the individual building blocks (transactions) they used to make those proofs to their settlement layer.
Block space on that settlement layer is limited. But proving that it’s possible to reconstruct all transactions - that the data is available - by posting data back to a settlement layer was previously the only way to use Layer 2s without significantly increasing the need for trust.
Avail changes this model.
Avail Layer
Let’s dive into the technology behind the bottom building block, the Avail layer.
Avail turns rollups into validiums. Let’s break down what that means. As we mentioned earlier, rollups are a type of execution environment.
In the ZK rollup case, they function by posting all of the transaction data they’ve executed as well as a small proof of execution to Ethereum. They become Validiums when they instead post their data to Avail, and a small proof (the same execution proof as before) to Ethereum.
You can see the impact that has on how much free space the settlement has at its disposal below.
Chains using Avail are asked to post all of their transaction data to Avail instead of Ethereum. Avail is then able to store, and prove availability of that data much more efficiently than other chains. Execution layers can then post an attestation to Ethereum saying either they, or the Avail validator set, has confirmed availability of the data in question.
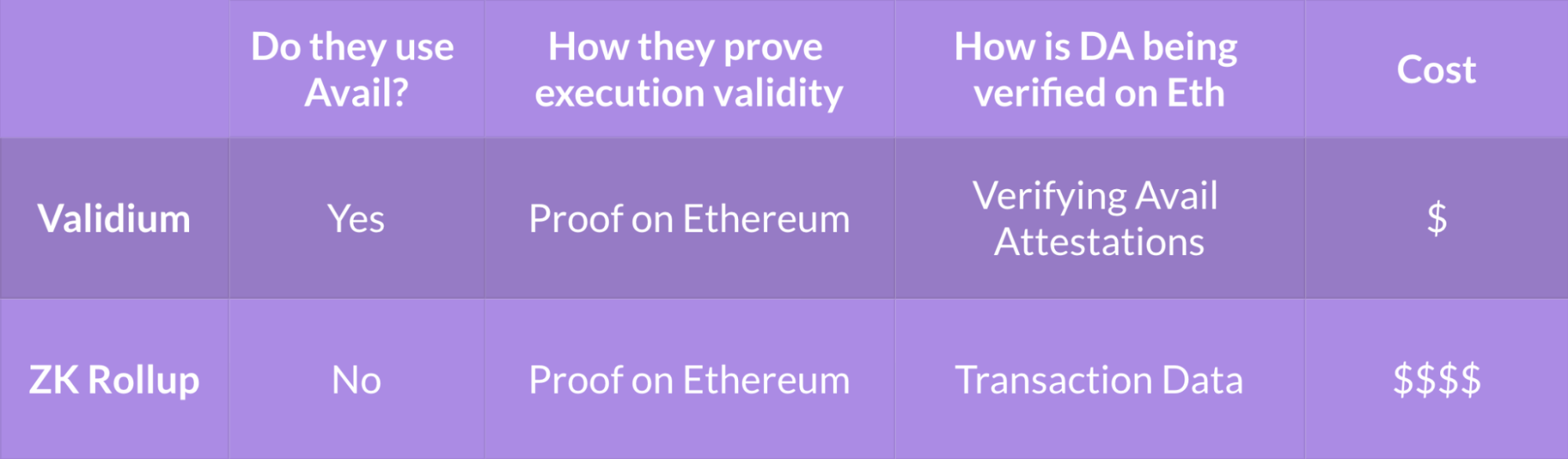
By replacing the need to post all of their transaction data to Ethereum with a small data attestation, execution environments can experience a substantial reduction in costs.
Avail’s data availability efficiencies come from how we have blended battle-tested data concepts like erasure coding with new data concepts like KZG polynomial commitments. You can read more about how these work in our previous blog posts (link).
The result is a data availability layer that only stores the transactions that execution layers say they received in the order Avail says they received them. From there, any application’s users are assured that the ordered data is available and can themselves reconstruct the application state at any point they wish.
Where a blockchain stores its transaction data may seem like a subtle shift in design, but it enables a radical shift in what blockchains can accomplish. Read more about our vision for Avail, and the modular blockchain future here.
We hope you’re as excited about the modular blockchain future as we are.If you want to learn more about Avail, or just want to ask us a question directly, we would love to hear from you. Check out our repository, join our Discord server.
This article was originally published on Polygon's official blog.