

The Avail Mainnet is now live. As users begin incorporating Avail into their chain designs, a question that often comes up is, “How many transactions can Avail process?” This is the second piece in a three-part series of articles that will address Avail’s current performance, as well as its ability to scale in the near and long term. You can read Part One here.
In Part One of this series, we explored how Avail operates today. In part 2, we’ll make it clear that we can scale (by increasing the block size) quite quickly. We’ll walk through precisely how and why that is possible. We’ll introduce the concepts that will allow us to scale Avail beyond simple block size increases. And we’ll introduce exactly where interventions to increase throughput are going to come in the Avail block production, and verification process.
So, let’s explore the most straightforward way to scale Avail: increasing block size.
Current Experimental Results
As we’ve played around with different block sizes for Avail, we’ve learned that rows and columns in the Avail data matrix must be treated differently.
In an Avail block:
- number of rows = number of polynomial commitments to build
- number of columns = degree of polynomial (how complex each individual commitment is to build)
The three things that must be done before a light client can reach a data availability guarantee are as follows:
- Commitments must be built - As mentioned in Part One of this series, commitments are generated by block producers, and are built using an entire row of data in the Avail matrix.
- Proofs must be generated - Proofs are generated for every single cell in Avail’s data matrix. While an individual proof is quick to produce, we must be aware of the impact adding more rows and columns has on the amount of proofs that need to be generated.
- Proofs need to be verified - In Avail’s current model, light clients download a cell’s value, a cell’s proof, and compare them to the information contained in that cell’s row’s commitment to verify they downloaded a matching piece of data.
The thing is, there’s a constant tradeoff between the time it takes to build commitments, and the time it takes to handle proofs. This becomes especially salient as Avail’s block size is increased.
Increasing Avail’s block size
The main tension when increasing the block size of Avail can be described as commitment generation (performed by validators), versus proof generation & verification (performed by full nodes & light clients, respectively).
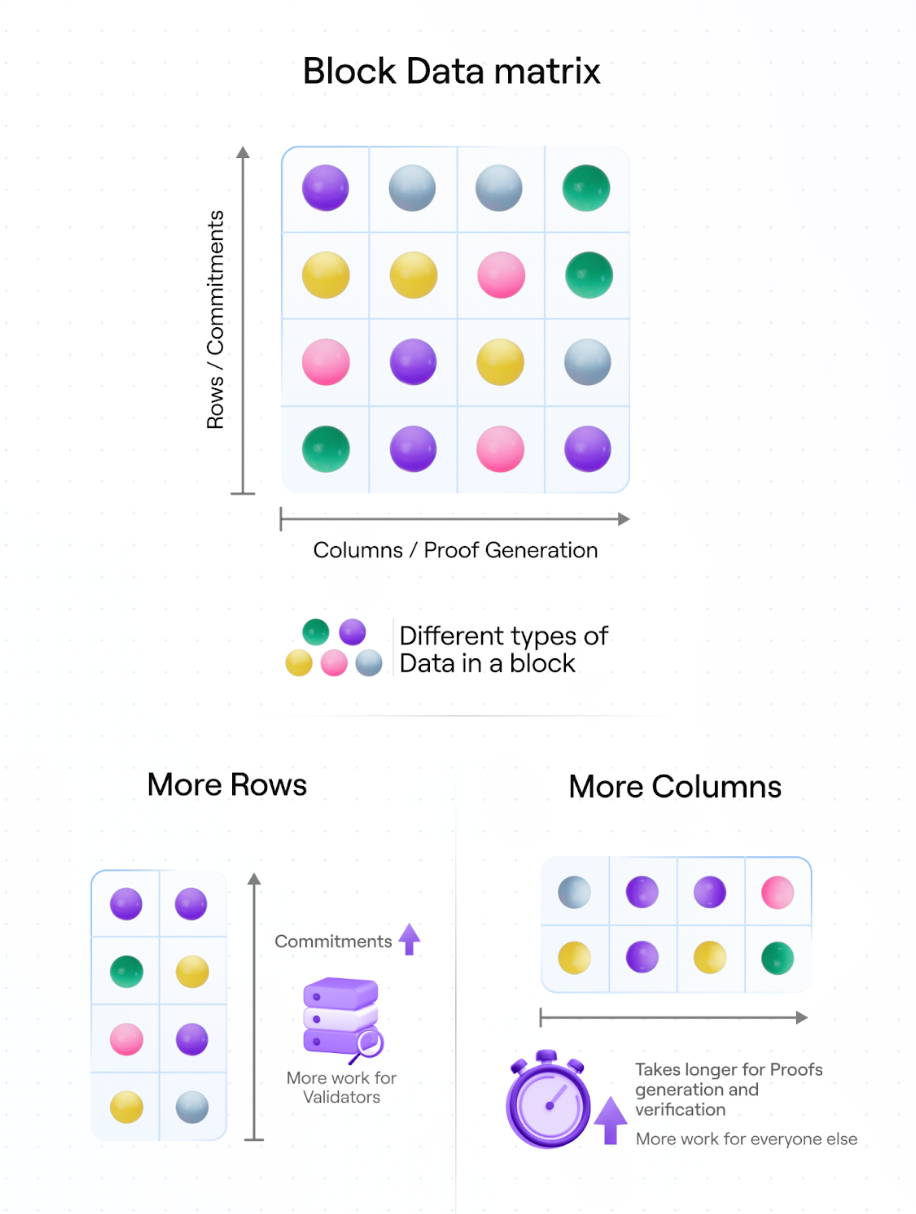
The more rows included in a block’s data matrix, the longer the block generation time. This is because more rows means producers must create more commitments (think of commitments as more advanced state roots).
Conversely, the more columns, the more time it takes to build and verify proofs as we’re dealing with polynomials of higher degree. For more details on the inner workings of the KZG polynomial commitment scheme that underpins Avail’s architecture, this post by Dankrad Feist shares more information.
For example, currently Avail has a 256x256 matrix (~65K cells). In order to double the block size, we can:
- double the columns to make it 256x512
- double the rows to make it 512x256
- some other ratio in between
Doubling the block size should always result in ~131K cells, double the 65K we have now.
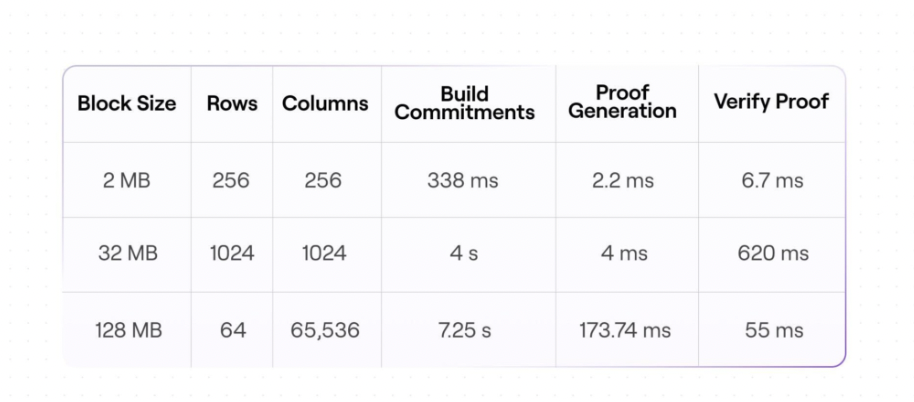
Keeping this in mind, we could increase the size of an Avail block from the current 2 MB to 32 MB. This is quite achievable in the near future. For example, a 1024x1024 (32 MB) Avail block takes 4s to generate commitments, 4ms to build a proof, and 620ms to verify a proof. These numbers suggest that a 32 MB block can have commitments generated, all proofs built, and verified within the current 20s block limit.
And, there’s plenty of computation headroom to increase block sizes beyond even 32 MB. An Avail block of 128 MB with dimensions 64x65,536 takes 7.25s to generate commitments, 174ms to build a proof, and 55ms to verify a proof.
This provides us with a realistic computational limit on what can be accomplished by the producers generating commitments, and full nodes generating cell proofs within 20 seconds.
With block sizes of ~128 MB though, the network as a whole begins running into bandwidth constraints. Propagating blocks of that size over typical Internet speeds begins to present a real challenge. This is a common scaling bottleneck that will be faced by all data availability layers.
The numbers below show our experimental results for block sizes of 2 MB, 32 MB, and 128 MB with varying row to column ratios. You can find more of our results here.
How Avail’s design guarantees low prices
Over the course of this series, we've focused on the technical methods we could implement to enable the Avail network to handle more and more transactions per second. Just as important to consider in any blockchain based system are the incentives to scale, as well.
As the network grows, validators will incur the cost of scaling. Should Avail become sufficiently decentralized, validators will have their own interests independent of Avail.
Rest assured that as Avail both decentralizes and grows, validators will be incentivized to keep prices low. As each throughput limit is reached, growth allows for the possibility of increased gas fees via rent-seeking validators.
However, Avail’s design fosters the continued growth of transaction throughput (and affordability of transaction costs), even in a fully decentralized system.
If you keep cost per transaction the same while increasing block size, validators end up with the opportunity to make much more money overall. Validators can get access to a larger and larger pool of users. We don’t have to limit how many users Avail can support in the way blockchains that handle execution have to. Computing constraints are no longer the limiting factor on growth. That means that as long as prices stay low, the total number of transactions will continue to increase.
As the network grows, and validators are able to capture value, validators also get to take advantage of economies of scale.
Thus, the “marketplace” we’re creating with Avail is one that can offer consistent growth to a network of validators, while offering consistently low cost per transaction to users.
The Avail testnet is already live with updated versions on the way. As works toward the mainnet, we’re interested in partnering with any teams looking to implement data availability solutions on their chains.If you want to learn more about Avail, or just want to ask us a question directly, we would love to hear from you. Check out our repository, join our Discord server.
This article was originally published on Polygon's official blog.