
This is the first piece in a three-part series of articles that will address Avail’s current performance, as well as its ability to scale in the near and long term.
The Avail Testnet is now live. As users begin incorporating Avail into their chain designs, a question that often comes up is, “How many transactions can Avail process?” We’ve already published pieces that outline how Avail is technically implemented. To start, we’ll compare the throughput of Ethereum to Avail given both chain’s current architecture.
Avail vs Ethereum
Ethereum blocks can hold a maximum of 1.875 MB, with a block time of ~13 seconds. However, Ethereum blocks are usually not filled. Nearly every block hits the gas limit before the data limit is reached, because both execution and settlement costs gas. As a result, the amount of data stored per block is variable.
The need to combine execution, settlement, and data availability in the same block is the core problem with monolithic blockchain architectures. Layer-2 (L2) rollups started the modular blockchain movement by allowing execution to be handled on a separate chain, with blocks dedicated solely to execution. Avail takes modular design one step further by decoupling data availability, as well, and allowing for a chain with blocks dedicated solely to data availability.

Currently, Avail has a block time of 20 seconds with each block capable of holding around 2 MB of data. Assuming an average transaction size of 250 Bytes, each Avail block today can hold around 8,400 transactions (420 transactions per second).
More importantly, Avail can consistently fill blocks right up to the storage limit, and increase size as needed. There are numerous levers we can pull - many quite quickly - to get that number above 500,000 transactions per block (25,000 transactions per second) as the need arises.
Can we increase throughput?
To increase throughput (specifically, transactions per second), chain architects either need to increase the block size, or decrease the block time.
To be added to the chain, each block must produce commitments, build proofs, propagate them, and have all other nodes verify the proofs. These steps will always take time, and provide a bound on block times.
As a result, we can’t just reduce block time to something like one second. There would not be nearly enough time to produce commitments, generate proofs, and propagate these pieces to all participants across the entire network. At a theoretical block time of one second, even if every network participant was running the most powerful machines that could instantaneously produce commitments and proofs, the bottleneck is the propagation of data. The network is unable to communicate the block to all full nodes quickly enough due to internet speed constraints. So we must make sure block time is high enough to allow for the distribution of data across the network after consensus is reached.
Instead, increasing throughput will come by increasing block size -- an increase in the amount of data we can include in each block.
Current Architecture: Adding a block to the chain
To start, let’s take a look at what’s required to add a block to the chain. Adding each block to the chain requires three main steps. The time it takes to produce a block, propagate that block, and verify said block.
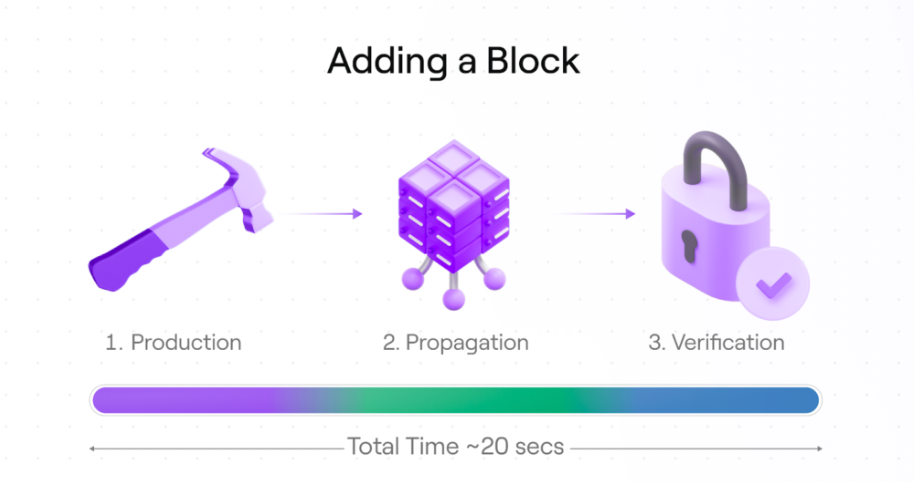
1. Block production
This step includes the time it takes to collect and order Avail transactions, build commitments, and extend (erasure code) the data matrix.
Block production measures the time needed to produce a block because it always takes at least some time. As a result, we must consider not just the best-case time, but the average and worst-case time for different machines.
The weakest machine that can participate in the production of new blocks is the one whose capacity maxes out in the average-case time. All slower machines will inevitably end up falling behind, as they are unable to catch up to faster machines.
2. Propagation delay
Propagation delay is a measure of the time it takes to propagate blocks from producers to validators and the peer-to-peer network.
Currently, Avail has 2 MB blocks. Blocks of this size can be propagated within the current 20 second block time constraints. Larger block sizes makes propagation trickier.
If we were to increase Avail to support 128 MB blocks, for instance, computation would likely be able to scale (~7 seconds). However, the bottleneck then becomes the amount of time it takes to send and download these blocks across the network.
Sending 128 MB blocks across the globe over a peer-to-peer network in 5 seconds is likely the limit of what can be accomplished at this time.
The 128 MB limit has nothing to do with data availability or our commitment scheme, but is rather a matter of communication bandwidth constraints.
This need to account for the propagation delay provides us with our current theoretical block size limit for Avail.
3. Block verification
Once propagated, participating validators do not simply trust the block provided to them by a block proposer–they need to verify that the blocks produced actually have the data producers say they do.
These three steps present a bit of tension with each other. We could make all the validators powerful machines tightly connected by excellent networking in the same data center -- that would decrease production and verification times and let us propagate massively more data. But because we also want a decentralized, diverse network with different kinds of participants, that is not a desirable approach.
Instead, improvements in throughput will come by understanding which steps are required to add a block to the Avail chain, and which can be optimized.
Currently, validators using Avail take the entire block and reproduce all of the commitments generated by the proposer, in order to verify the block. This translates to both block producers and all validators performing every step of the graphic above.
This recreation of the entire block by each validator is the default in monolithic blockchains. However, it is not necessary on a chain like Avail, where transactions are not executed. As a result, one way we can optimize Avail is by allowing validators to reach their own guarantees of data availability via sampling, as opposed to block recreation. This places lower resource requirements on validators than if they were asked to reproduce all commitments. More on that in later posts.
Exploring how data availability sampling works
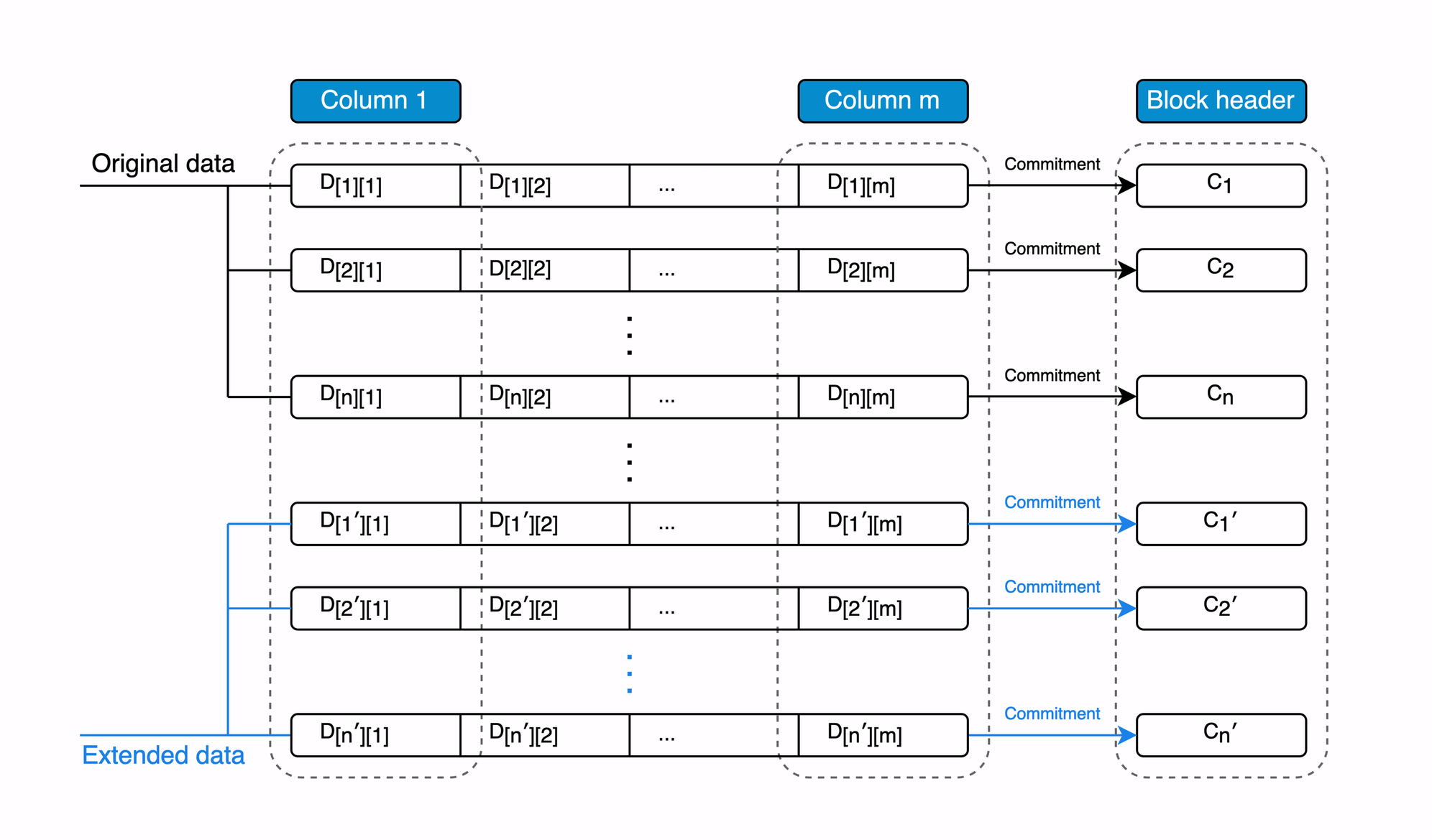
In Avail, light clients reach confirmations of data availability using three core tools: samples, commitments, and proofs.
- Samples are currently performed by light clients, and involve them asking the Avail network for a specific cell’s value, and that cell’s associated validity proof. The more samples they take, the more confident they can be that all data is available.
- Commitments are generated by block proposers, and summarize data in an entire row of an Avail block. (Hint: This is the step that we will be optimizing later in the series.)
- Proofs are generated for every individual cell in the network. Proofs are used in combination with the commitment by light clients to verify that the value of the cell provided to the light client is indeed correct.
Using these tools, light clients then perform three steps.
- Decide: The desired confidence of availability informs how many samples light clients perform. They don't need many samples (8-30 samples) to reach availability guarantees of above 99.95%.
- Download: Light clients then request these samples, along with their associated proofs, and download them from the network (from full nodes, or other light clients).
- Verify: They then look at the commitment in the block header (which light clients always have access to), and verify the proof for each cell against the commitment.
With that alone, light clients are able to confirm availability of all the data in the block without needing to download more than a tiny percentage of the block. There are other steps that light clients perform to contribute to the security of Avail that aren’t listed. For example, light clients are capable of sharing their downloaded samples and proofs with other light clients should they need it. But that’s it–that’s the procedure for light clients to confirm data availability!
In part 2 of this series, we’ll explore the ways we can improve the throughput of Avail in the short-term. We’ll explain why we’re confident that Avail is capable of growing to meet any network’s demands presented in the coming year, and how we can improve the network for years to come.
The Avail testnet is already live with updated versions on the way. As Avail works toward the mainnet, we’re interested in partnering with any teams looking to implement data availability solutions on their chains. If you want to learn more about Avail, or just want to ask us a question directly, we would love to hear from you. Check out our repository, join our Discord server.
This article was originally published on Polygon's official blog.