
What is Data Availability and Why Do Blockchains Need It?
One of the most important characteristics of any blockchain is that everyone in the system (computers and people too) have the same, shared source of truth.
Transactions that take place on a blockchain get recorded into blocks. When new blocks are being added to a blockchain, the transaction data needs to be made available. With this transaction data, full-nodes can verify the state of the blockchain, by re-executing the transactions, ensuring that state updates were done correctly.
If the transaction data is not made available, or if it can be manipulated in some way, it creates a vulnerability that malicious actors can exploit.
What About Data Availability for Rollups?
Rollups de-couple the operations of a blockchain by moving the computation required to execute transactions onto their own, separate blockchain, and data availability is a crucial component for both Optimistic and ZK Rollups. The Rollup network relies on the data-availability guarantees and security of a ‘base-chain’ that it is built on. Because the data is being made available on the base chain, anyone can access the data on that chain and recreate the Rollup. After a Rollup executes transactions, in most popular rollup constructs today, it will send a proof to show it executed the transactions correctly to the base-chain, periodically.
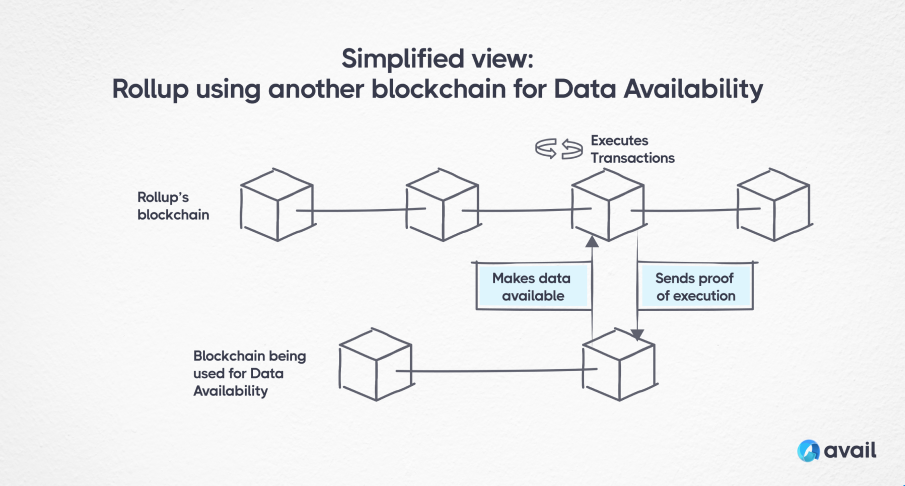
The benefits for developers building a Rollup are vast. If you can rely on another network for all the heavy lifting to make sure data is secure and available, you’ve drastically reduced the requirements for building and running a blockchain. A number of Rollups such as Arbitrum, Polygon, Optimism, Starknet, and zkSync have already successfully done this, building on Ethereum as their base chain. They have also begun offering their Rollup code so that others in the ecosystem can deploy their own blockchains too.
All of this innovation is great for the blockchain ecosystem as it’s becoming far easier for new developers to build and experiment with their own blockchains. This new reliance on, and demand for, data availability as a service, is creating a focal point for the blockchain ecosystem.
Ethereum is being used more and more as a data availability solution, even though it was never intended to be used in this way and as such its data availability throughput is limited. While the costs of publishing data on Ethereum have significantly reduced following EIP-4844, they are still prohibitively expensive for use cases that are sensitive to pricing like decentralized social media. This has led to an increase in demand for alternative DA solutions.
Why Is the Data Availability Problem So Hard to Solve?
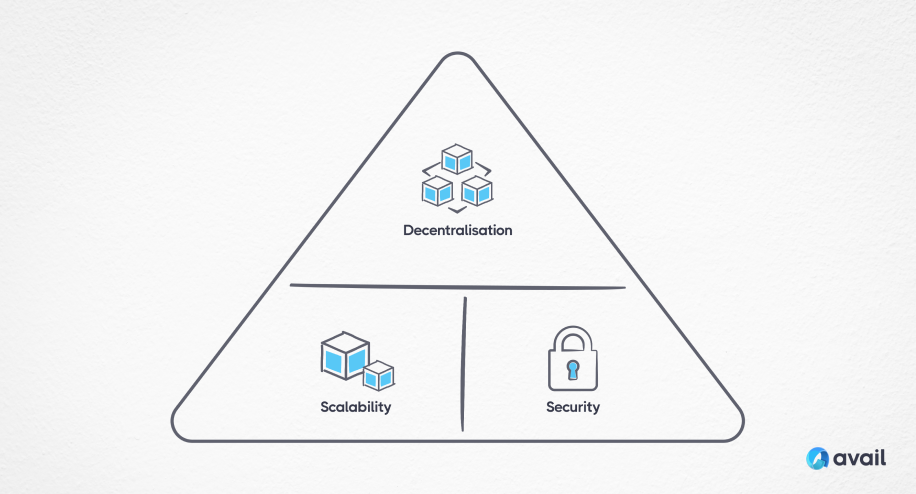
When looked at in isolation, the data availability problem is a unique one to solve. It goes to the heart of blockchain scalability. It requires a blockchain to be able to handle more data, while remaining decentralized and secure.
Data availability requires that all the nodes adding new blocks to the blockchain, be certain that the data is available every time a new block is added. However, when the blockchain grows in popularity, so too does the amount of transaction data that nodes need to maintain, and the demand for data availability rises.
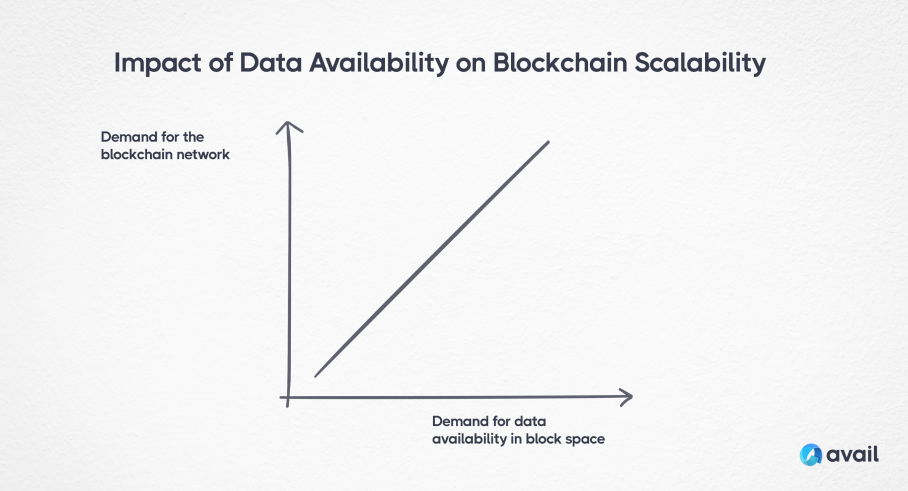
Transaction data can only be compressed so much, and for the blockchain to remain decentralized, a number of nodes need to be responsible for data availability. Increasing the amount of data recorded by the blockchain leads to bloat in the network.
In monolithic blockchain systems where the data availability process is just one other process embedded within the blockchain itself, it’s confronted with the blockchain scalability trilemma. In order to increase the amount of data availability capacity, a monolithic blockchain needs to provide an equivalent ability to scale execution. This is why the introduction of rollups has been so successful, freeing up execution to take place on a different blockchain and placing more demand on data availability. To achieve scale across both data availability and execution within a monolithic blockchain, you must trade-off either between decentralization, scalability or security.
Recent examples of data availability capacity limitations being met can be seen by those attempting to solve the data availability problem for high-throughput blockchains in gaming and decentralized social networks. With high demands for data availability, some teams have turned to Data Availability Committees (DACs). These small, often permissioned groups of organizations choose to run nodes to provide low-cost data availability services for other blockchains, often at the expense of security and/or decentralization.
If you have to trust the DAC to make all transaction data available, and you have no way of independently proving that transactions were being manipulated or hidden from blockchain nodes, then committee members introduce a vulnerability where they can collude to manipulate blockchain transactions.
Making transaction data available is clearly important, but what about the incentives? It requires a significant amount of computational resources to make the data available to nodes, so there needs to be some economic incentive for doing so. These economic incentives can also be used to discourage bad behavior.
If a user is unable to independently verify data availability for themselves they will have to trust full-nodes, adding a centralizing force to the network's architecture. Economies of scale move the industry towards a position where a handful of providers act as trusted intermediaries to provide these data availability guarantees to users, dApps and other services. This is where the light clients come in to provide data availability guarantees to apps and users which can independently verify data availability for themselves.
Various teams and projects are attempting to address the data availability problem in different ways, however there are only a few purpose-built data availability solutions that have been built from the ground up to solve this very unique problem.
Modern Solutions to the Data Availability Problem
New purpose-built data availability solutions have become a hot topic in blockchain infrastructure circles, especially for rollup and app-chain developers. These new solutions provide affordable, decentralized data availability services on a separate and purpose-built system that is designed specifically to focus on solving the data availability problem.
These solutions, including Avail DA, are easy to integrate and act as a ‘pluggable’ data availability layer for other blockchains. Built from the ground up for data availability, and leveraging modern developments in ZK technology, Avail’s design choices enable it to scale with demand and efficiently provide data availability guarantees for entire networks of blockchains built on top.
If you’re considering using a purpose-built data availability solution, then it’s important to find one that suits your needs. You can check out this comparison of different data availability solutions or learn more about Avail’s core features to see if it’s right for you.